主讲:老孙
适用:2026年下半年系统规划与管理师考试
预计阅读时间:50分钟
一、上节回顾
上一讲我们建立了数字化转型的"总纲"——信息化 / 数字化 / 智能化三级跳、5 大维度、4 阶段路线图。今天我们进入"前沿应用 8 大技术"的第 1 讲——大数据。
大数据为什么放在 8 大技术第 1 讲?因为它是数字化的基石。没有数据 = 没有数字化;没有大数据能力 = 数字化跑不动。
我做了 20 年项目,看过太多组织。能用好数据的组织 = 真正在做数字化;不能用好数据的组织 = 只是"信息化升级"。两者的差距 = 一个时代的差距。
1.1 大数据的"3 大业务价值"
第一,洞察价值——数据告诉我们"业务真实情况"。
第二,预测价值——数据让我们提前知道"业务未来走向"。
第三,创造价值——数据本身可以"成为商品"。
3 大业务价值 = 大数据对组织的不可替代性。
1.2 大数据时代的"3 个事实"
事实 1:全球数据量年增长 30%+——每 2-3 年翻一倍
事实 2:80% 的企业声称"重视数据"——但只有 20% 真正用好数据
事实 3:数据已被纳入"生产要素"(与土地、劳动力、资本、技术并列)——这是国家层面的定位
3 大事实 = 大数据的"时代背景"。
二、本讲导读
2.1 学习目标
- 【是什么】 准确说出大数据的"5V 特征"、技术栈、典型架构、数据治理 DCMM 五级
- 【为什么】 理解大数据为何是数字化基石——所有数字化转型最终都要落到"数据用得好不好"
- 【怎么用】 能为一个组织设计大数据体系框架与 3 年数据治理路线
2.2 本讲在课程地图中的位置
本讲对标教材 第 15 章 大数据——是阶段四的"基础设施"章节。
2.3 一句话理解大数据
大数据 = 体量超大、速度超快、种类超多、价值密度超低的数据集合,需要全新技术架构与治理体系才能驾驭。
【虚构案例提示】 本讲涉及"智慧邻里2.0项目""清华园物业""北京知知致用信息技术有限公司"均为培训教学所用的虚拟项目与虚构人物(详见第01讲首次案例声明)。
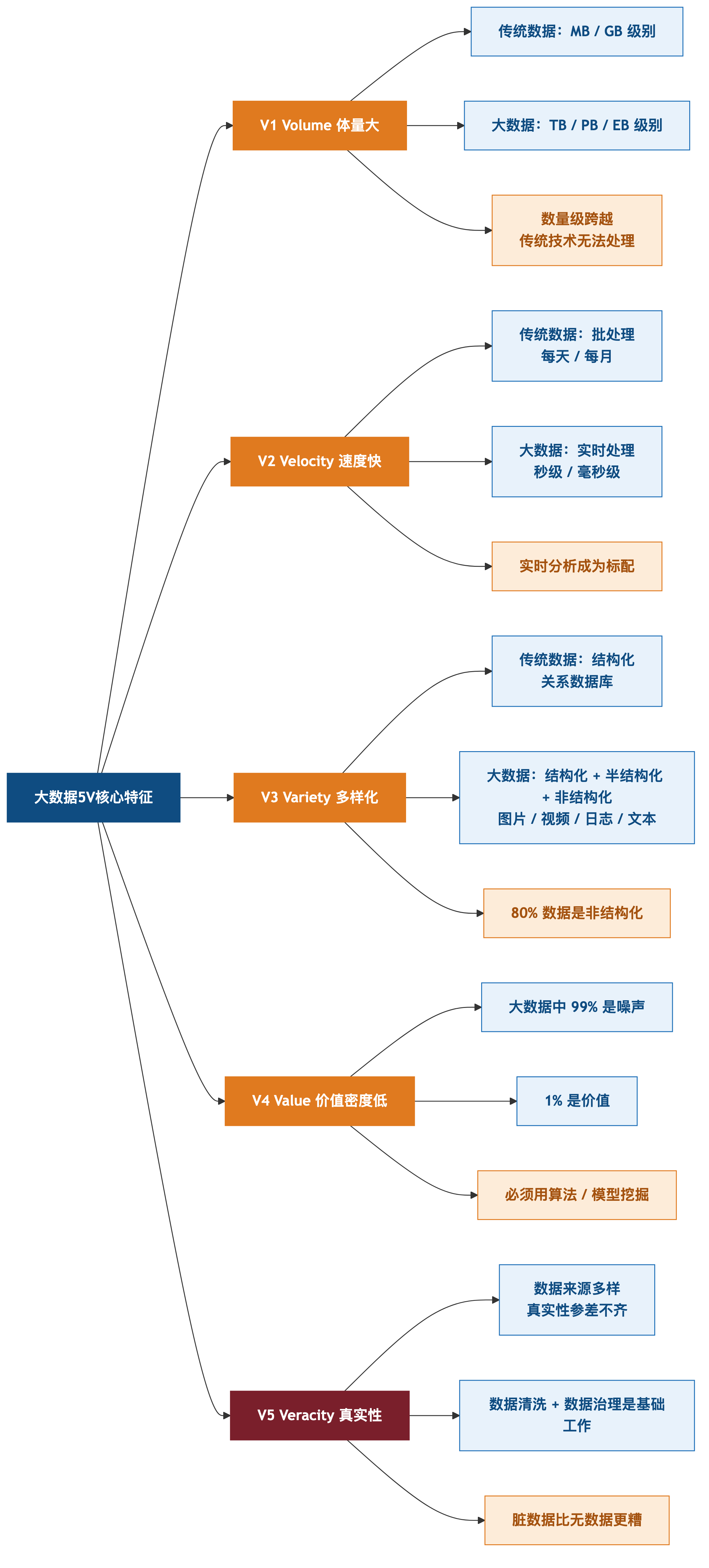
三、大数据的"5V 核心特征"
3.1 5V 完整解读
大数据相对于传统数据的核心差异由 5V 特征定义——这是系规考试的"必背"。
V1:Volume(体量大)
- 传统数据:MB / GB 级别
- 大数据:TB / PB / EB 级别
- 数量级跨越 = 传统技术无法处理
V2:Velocity(速度快)
- 传统数据:批处理(每天 / 每月)
- 大数据:实时处理(秒级 / 毫秒级)
- 实时分析成为标配
V3:Variety(多样化)
- 传统数据:结构化(关系数据库)
- 大数据:结构化 + 半结构化 + 非结构化(图片 / 视频 / 日志 / 文本)
- 80% 数据是非结构化
V4:Value(价值密度低)
- 大数据中 99% 是"噪声"
- 1% 是"价值"
- 必须用算法 / 模型挖掘
V5:Veracity(真实性)
- 数据来源多样 = 真实性参差不齐
- 数据清洗 + 数据治理是基础工作
- "脏数据"比"无数据"更糟
5V 特征 = 大数据"DNA"。背熟这 5 个 V = 选择题 90%+ 命中。
3.2 清华园物业的"5V 实况"
V1 体量:
- 物业全量数据约 5TB(含历史)
- 视频监控数据约 50TB / 年
- 业主行为数据约 100GB / 年
V2 速度:
- 缴费 / 报修 / 安防数据实时入库
- 业主 APP 行为流实时分析
- 监控告警秒级响应
V3 多样:
- 结构化:缴费记录、报修工单、业主信息
- 半结构化:APP 日志、设备日志
- 非结构化:监控视频、电话录音、图片
V4 价值密度:
- 监控视频 99% 是"无事件画面"
- 1% 是"安防事件"
- 必须用 AI 算法识别
V5 真实性:
- 业主自报数据有失真
- 设备数据有故障
- 必须数据清洗 + 质量监控
清华园物业 5V 实况 = 大数据特征的"具象化"。
3.3 5V 之外的"扩展 V"
有些学者提出 5V 之外的扩展 V,了解即可(考试以 5V 为准)。
- V6 Visualization(可视化)—— 数据要可看见
- V7 Variability(可变性)—— 数据是动态的
考试时严格按 5V 答题——扩展 V 不要答。
四、大数据技术栈
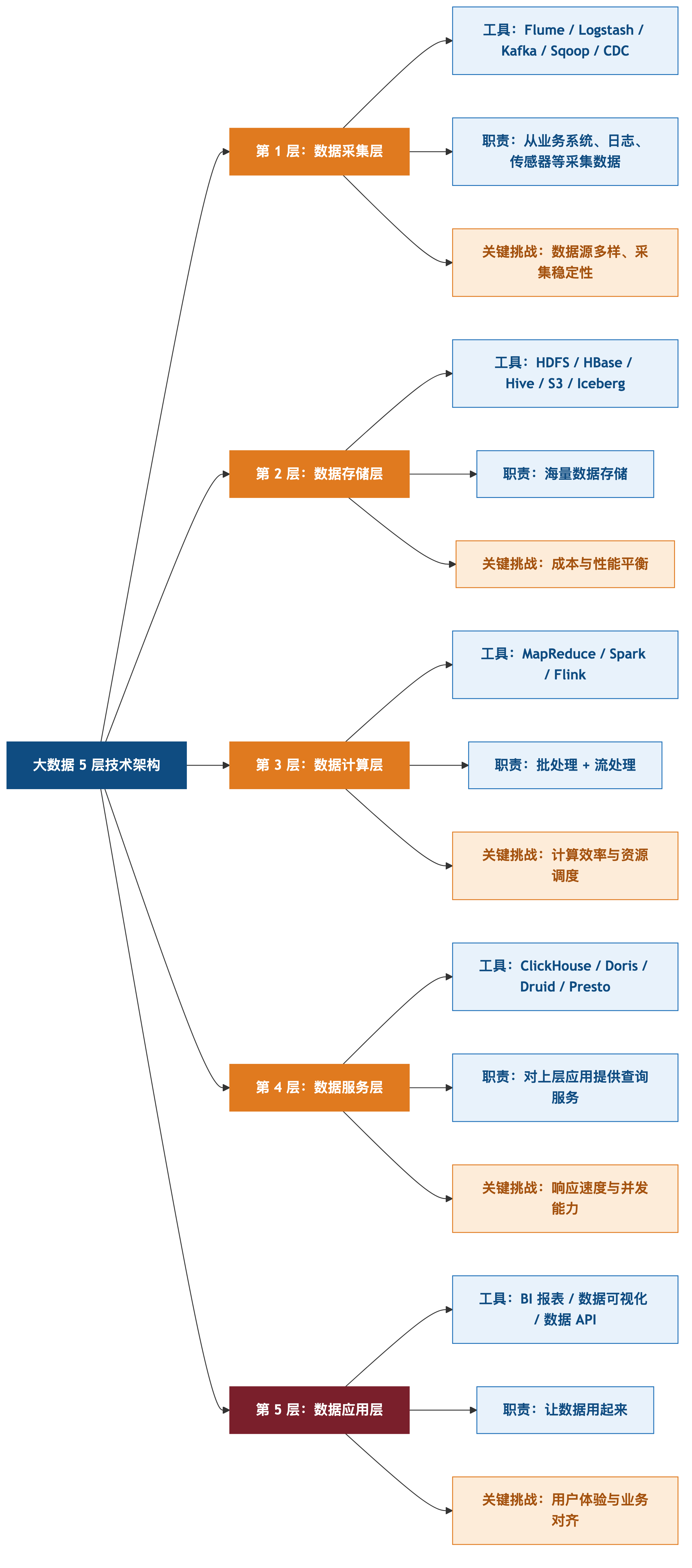
4.1 大数据"5 层技术架构"
完整的大数据技术栈分 5 层。
第 1 层:数据采集层
- 工具:Flume / Logstash / Kafka / Sqoop / CDC
- 职责:从业务系统、日志、传感器等采集数据
- 关键挑战:数据源多样、采集稳定性
第 2 层:数据存储层
- 工具:HDFS / HBase / Hive / S3 / Iceberg
- 职责:海量数据存储
- 关键挑战:成本与性能平衡
第 3 层:数据计算层
- 工具:MapReduce / Spark / Flink
- 职责:批处理 + 流处理
- 关键挑战:计算效率与资源调度
第 4 层:数据服务层
- 工具:ClickHouse / Doris / Druid / Presto
- 职责:对上层应用提供查询服务
- 关键挑战:响应速度与并发能力
第 5 层:数据应用层
- 工具:BI 报表 / 数据可视化 / 数据 API
- 职责:让数据"用起来"
- 关键挑战:用户体验与业务对齐
5 层技术架构 = 大数据"完整骨架"。
4.2 批处理 vs 流处理 vs 实时
大数据计算分 3 大模式。
模式 1:批处理(Batch)
- 数据攒一批一起处理
- 适合:T+1 报表、月度分析
- 工具:Hadoop MapReduce / Spark
- 延迟:分钟级到小时级
模式 2:流处理(Stream)
- 数据流入实时处理
- 适合:实时风控、实时推荐
- 工具:Flink / Storm / Kafka Streams
- 延迟:毫秒级到秒级
模式 3:实时分析(Interactive)
- 用户输入查询实时返回结果
- 适合:BI 看板、Ad-hoc 查询
- 工具:ClickHouse / Doris / Presto
- 延迟:秒级
3 大模式按场景选择——清华园物业三种都用。
4.3 数据湖 vs 数据仓库 vs 湖仓一体
数据存储有 3 大形态。
数据仓库(Data Warehouse):
- 结构化数据为主
- 严格 schema
- 适合:BI 与报表
- 代表:Hive / Teradata / 阿里 MaxCompute
数据湖(Data Lake):
- 原始数据全部进
- 弱 schema
- 适合:探索性分析 + AI 训练
- 代表:HDFS / S3 + Spark
湖仓一体(Lakehouse):
- 数据湖 + 数据仓库优点融合
- 适合:现代综合场景
- 代表:Delta Lake / Iceberg / Hudi
清华园物业 2024 年从"数据仓库"演进到"湖仓一体"——这是中型组织的合理路径。
五、数据治理与 DCMM 五级
5.1 数据治理的核心命题
数据治理回答 5 个核心命题。