主讲:老孙
适用:2026年下半年系统规划与管理师考试
预计阅读时间:55分钟
一、上节回顾
上一讲我们建立了 ITIL 的全局框架:
- ITIL 4 SVS 5 大要素
- 服务价值链 6 大活动
- 7 大指导原则
- 34 个实践 3 大分类
- ITIL v3 5 个生命周期
核心收获:"ITIL 是把 IT 部门从修电脑升级为提供五星服务的方法论。"
今天进入 ITIL 真正"接地气"的部分——四大核心流程。
1.1 为什么这四个流程是"核心中的核心"
ITIL 34 个实践里,最常用的是 4 个:
- 事件管理(Incident Management)
- 问题管理(Problem Management)
- 变更控制(Change Control)
- 发布管理(Release Management)
无论组织规模大小,这 4 个流程都是 IT 服务管理"日常作战"的主战场。
二、本讲导读
2.1 学习目标
学完这一讲,你应该能:
- 【是什么】 准确说出 4 个流程的定义、目标、输入输出、关键活动、关键角色
- 【为什么】 理解 4 个流程之间的衔接关系——事件触发问题,问题触发变更,变更带来发布
- 【怎么用】 能为一个组织设计 4 个流程的基本规则与 SOP
2.2 本讲在课程地图中的位置
本讲对标教材 第 12 章"IT 服务管理" 的"运营层"。
ITIL 三讲(28-30)的进度:
- 第 28 讲:服务理念(已完成)
- 第 29 讲(本讲):四大核心流程
- 第 30 讲:SLA 与服务级别管理
2.3 一句话理解四大流程
事件 = 救火、问题 = 防火、变更 = 改造、发布 = 投产——四件事合在一起,就是 IT 运营的"主战场"。
【虚构案例提示】 本讲涉及"智慧邻里2.0项目""清华园物业""北京知知致用信息技术有限公司"均为培训教学所用的虚拟项目与虚构人物(详见第01讲首次案例声明)。
三、事件管理(Incident Management)
3.1 什么是"事件"
定义:事件指 IT 服务的非计划中断、质量下降或某项配置项的故障(不论是否已经影响服务)。
通俗理解:
- "邮件登不上"——事件
- "OA 系统打不开"——事件
- "打印机卡纸"——事件
- "网络掉线"——事件
关键词:未计划、影响服务。
3.2 事件管理的目标
事件管理的目标只有 一个:
尽快恢复服务——而不是查清原因。
这是事件管理与问题管理最大的区别——事件管理要"快",问题管理要"准"。
3.3 事件的分类
事件按 优先级矩阵 分类:
矩阵维度:
- 影响度(Impact):影响多少人、影响多严重
- 紧急度(Urgency):多急
优先级 = 影响度 × 紧急度:
| 优先级 | 影响 | 响应时长 | 解决时长 |
|---|---|---|---|
| P1 紧急 | 全公司停摆 | ≤15 分钟 | ≤4 小时 |
| P2 高 | 多部门受影响 | ≤1 小时 | ≤8 小时 |
| P3 中 | 单部门受影响 | ≤4 小时 | ≤24 小时 |
| P4 低 | 单用户受影响 | ≤8 小时 | ≤72 小时 |
清华园物业的事件分级:
- P1:全小区缴费/报修瘫痪
- P2:单楼栋系统故障
- P3:单业主报修不能在线提交
- P4:业主 APP 个别功能小问题
分类决定响应——分错类整个流程就乱。
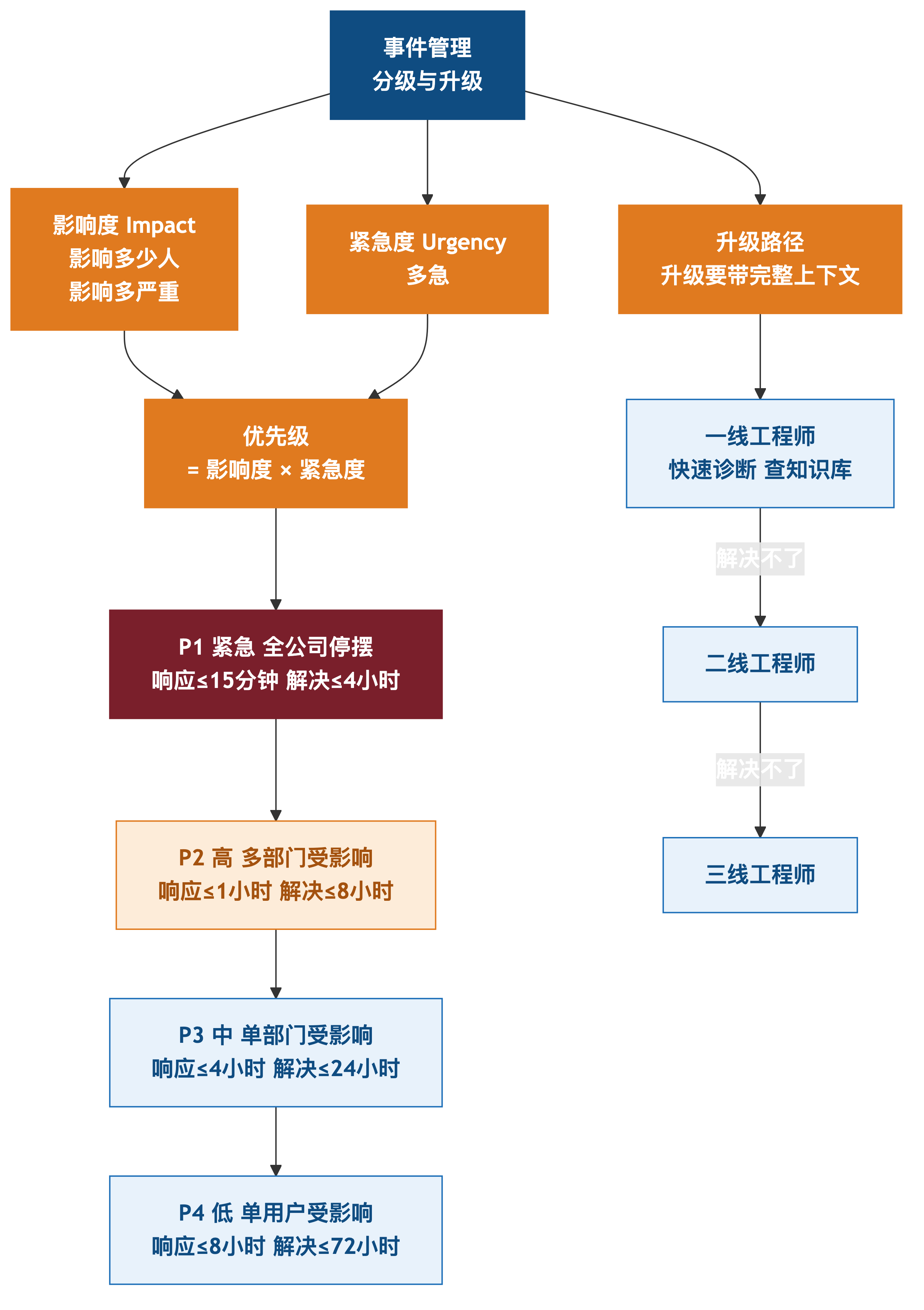
3.4 事件管理的标准流程
事件管理有 9 大步骤:
步骤 1:事件识别
- 谁发现:用户、监控系统、服务台
- 通过什么:电话、邮件、APP、自动告警
步骤 2:事件记录
- 在 ITSM 系统中创建工单
- 关键字段:时间、人、现象、影响范围
步骤 3:事件分类
- 按服务类别(邮件 / 网络 / 应用 / 硬件)
- 按优先级(P1-P4)
步骤 4:初步诊断
- 一线工程师快速判断
- 查询知识库
步骤 5:升级
- 一线解决不了 -> 二线
- 二线解决不了 -> 三线
- 升级要带"完整上下文"
步骤 6:调查与诊断
- 进一步排查
- 排除可能原因
步骤 7:解决与恢复
- 实施解决方案
- 验证服务恢复
步骤 8:事件关闭
- 用户确认满意
- 沉淀知识
步骤 9:复盘
- P1/P2 必须做事后复盘
- 输出改进点
9 步走完 = 一次完整的事件管理。
3.5 事件管理的关键指标
- 首次响应时长(FRT)
- 平均解决时长(MTTR)
- 首次解决率(FCR)
- SLA 达成率
- 重复事件率
5 大指标 = 事件管理的"体检表"。
3.6 清华园物业的事件管理案例
场景:周一早 9 点,全小区缴费系统打不开
P1 紧急事件处理:
- 09:00 业主在 APP 反馈,监控同时告警
- 09:05 服务台创建 P1 工单,电话通知 IT 负责人
- 09:10 IT 负责人召集二线工程师
- 09:25 排查到数据库连接池满
- 09:40 重启数据库连接池,服务恢复
- 10:00 服务台向业主推送恢复通知
- 14:00 当天召开复盘会,输出 3 项改进
- 次日产生 1 个"问题工单"(深挖根因)
总耗时 40 分钟——P1 SLA 4 小时内完成。
四、问题管理(Problem Management)
4.1 什么是"问题"
定义:问题指一个或多个事件背后未知的根本原因。
通俗理解:
- "邮件系统每周都崩一次"——这背后是"问题"
- "打印机经常卡纸"——这背后是"问题"
事件 vs 问题:
- 事件:现象(一次一次发生)
- 问题:根因(事件背后的真正原因)
4.2 问题管理的目标
问题管理的目标是 3 个:
- 防止事件再次发生
- 减少事件影响
- 沉淀已知错误(Known Error)
问题管理 = "防火"——不是修当前的火,是防下次再着火。
4.3 问题的两大类
反应型问题管理(Reactive):
- 由事件触发
- "已发生事件的根因分析"
主动型问题管理(Proactive):
- 由趋势分析触发
- "潜在问题的提前发现"
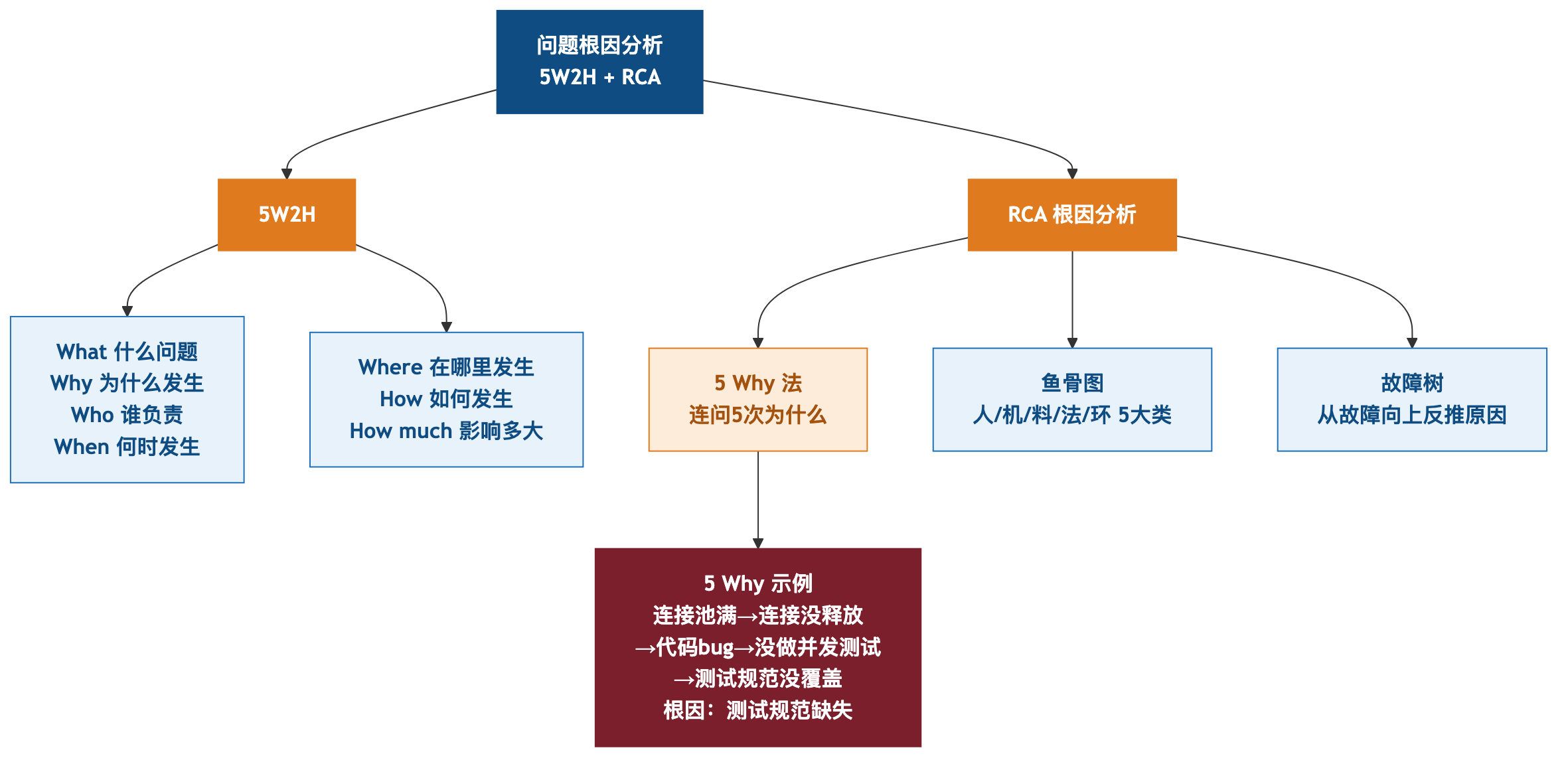
4.4 问题分析的"5W2H + RCA"工具
5W2H:
- What(什么问题)
- Why(为什么发生)
- Who(谁负责)
- When(何时发生)
- Where(在哪里发生)
- How(如何发生)
- How much(影响多大)
RCA(Root Cause Analysis):
- 5 Why 法:连问 5 次为什么
- 鱼骨图:人/机/料/法/环 5 大类
- 故障树:从故障向上反推原因
例子(清华园物业):
- 问题:缴费系统经常崩
- 5 Why:
1. 为什么崩?数据库连接池满
2. 为什么满?连接没释放
3. 为什么没释放?代码 bug
4. 为什么有 bug?没做并发测试
5. 为什么没测?测试规范没覆盖 - 根因:测试规范缺失
5 Why = 把"现象"挖到"根因"的最简单工具。
4.5 已知错误数据库(KEDB)
KEDB(Known Error Database) 是问题管理的核心产物:
- 记录每个"已知错误"
- 包含:现象、根因、临时方案、永久方案
KEDB 的价值:
- 一线服务台快速参考
- 减少重复事件
- 沉淀组织知识资产
清华园物业 KEDB 经过 1 年沉淀,有 200+ 条已知错误。
4.6 问题管理的关键指标
- 问题解决率
- 平均问题解决时长
- 由问题转事件预防数
- KEDB 沉淀数
五、变更控制(Change Control)
5.1 什么是"变更"
定义:变更指对 IT 服务及其相关配置项的任何新增、修改或删除。
通俗理解: