主讲:老孙
适用:2026年下半年系统规划与管理师考试
预计阅读时间:40分钟
一、上节回顾
上一讲我们一起挖了"系规"知识大厦最底下的三块基石:信息、信息化、信息系统。
我用了菜市场、厨房、餐厅这三个最朴素的场景,把这三个看似一模一样、其实差着十万八千里的概念给你掰开揉碎了。如果你跟着我的节奏走完了,那现在你脑子里应该已经有了下面这张"概念三连"图:
数据是原材料,信息是经过加工的数据,信息化是用信息技术重塑业务过程,信息系统是支撑信息化的工具集合。
我也把这门课的"作战地图"完整地画给了你。80讲、7个阶段、180天,从今天开始,一步一个脚印往前走。
我还特别强调了三明治学习法:教材速览—讲义精讲—刷题复盘,三层咬合,才能把一个知识点真正吃透。
1.1 上一讲思考题深度解析
我看了不少同学传给我的课后作业。这里我挑出三个最典型的问题,给大家做个公开点评。
第一个问题,关于"我家公司上了钉钉就算信息化了吗"
90%的同学都答对了"不算",但理由说得参差不齐。我看到最深刻的一个回答来自一位国企的财务主管,她说:"我们公司也上了钉钉,但报销流程还是要先把纸质发票贴上、领导签字、扫描、再上传系统。这是把纸质流程往电子化套了一层壳,根本没有改变流程本身。"
说得太对了。
信息化的本质不是"把工具换成电脑",而是"用信息技术重塑业务过程"。一个组织如果只是把工具换了,业务流程、岗位职责、绩效考核、组织结构全都没动,那这种"信息化"就是 伪信息化。
后续在第43讲讲企业数字化转型的时候,我会带你深入剖析"伪信息化"和"真数字化"的差别。今天先把这个意识种下来。
第二个问题,关于"清华园物业的失败原因"
有些同学的反思非常深入。一位三线城市的物业经理写道:"我们小区也搞过类似的系统,最后失败的原因是物业领导只关心装多少摄像头、装什么品牌的门禁,根本没有人去问'装了之后业主报修的体验会不会更好、物业费会不会更容易收上来、安保人员的工作效率会不会更高'。"
这一段反思,已经触及了 系统规划师 的核心价值——业务视角。
记住:系统规划师永远是从业务出发、最后回到业务,技术只是中间的工具。
第三个问题,关于课后角色扮演——"张主管的内部备忘录"
我看到几份非常用心的备忘录。有的同学甚至替张主管设计出了"反思五条"。这种把自己代入角色的训练,是后续案例分析答题的核心能力。强烈建议 你把这个习惯保持下来:每讲都尝试至少代入一个案例角色。
好,回顾结束。今天我们要做一件深一些的事——把 DIKW 模型从"知道"变成"通透"。
二、本讲导读
2.1 学习目标
学完这一讲,你应该能够:
- 【是什么】 准确说出数据、信息、知识、智慧四个层级的定义、特征和差异;理解数据的三种形态(结构化、半结构化、非结构化);掌握数据生命周期的七个阶段。
- 【为什么】 理解为什么"数据驱动决策"是这个时代的主旋律;理解一个组织从数据使用到智慧管理之间存在的"四道断层"。
- 【怎么用】 能够分析一个组织当前在 DIKW 模型上的位置,并指出向上升级的具体路径。
2.2 本讲在课程地图中的位置
本讲是第01讲的纵向加深。如果说第01讲是"横向铺开"——把信息系列三个概念都过了一遍,那么本讲就是"纵向打井"——把"信息"这一个词钻到底。
本讲为后续这些章节打基础:
- 第18-20讲:数据资源规划与治理(数据治理的方法论根基)
- 第15讲:网络环境规划(数据传输的物理基础)
- 第43-44讲:企业数字化转型(数据驱动转型的逻辑起点)
如果你跳过本讲,后续这些章节会感觉"踩棉花"——能学,但不扎实。
2.3 一句话理解 DIKW
整个 DIKW 模型,可以用一句话概括:
数据是矿石,信息是钢材,知识是机器,智慧是工厂的运营哲学。
这一讲我会帮你把这句话彻底"装进脑子"。
三、第一层:数据的本质与三大形态
3.1 数据是什么?比你想的更复杂
教材给数据的定义是这样的:
数据是对客观事物的性质、状态以及相互关系等进行记载的物理符号或这些物理符号的组合。
读起来很正经,对吧?但其实里面藏了三个关键词,请你重点圈出来:
- 客观事物——数据必须有现实的源头
- 物理符号——数据必须依附在某种载体上
- 组合——数据不一定是单个符号,也可以是多个符号的有序集合
我用最简单的例子拆给你看:
| 例子 | 客观事物 | 物理符号 | 组合 |
|---|---|---|---|
| 温度计上显示"23℃" | 房间的温度 | 数字23+单位℃ | 数值与单位组合 |
| 监控录像里2分37秒的画面 | 那一瞬间的画面 | 视频帧+音频流 | 多媒体组合 |
| 业主张大爷的报修记录 | 张大爷家厕所漏水这件事 | 文字+时间+地点+视频 | 多类型字段组合 |
| 一段微信语音 | 业主说话这件事 | 音频波形 | 单一形态 |
所以数据可以是数字、文字、图像、音频、视频、传感器读数,甚至是DNA序列、心电图、卫星图像。一切能被记录、能被传输、能被处理的"客观痕迹",都是数据。
3.2 数据的三种形态:结构化、半结构化、非结构化
这是 每年选择题必考 的知识点,请你务必牢牢记住。
第一种:结构化数据
特点:有固定的格式和明确的字段,能用关系型数据库(比如MySQL、Oracle)直接存储。
最典型的例子就是 Excel 表格:
| 业主姓名 | 房号 | 电话 | 物业费余额 | 缴费截止日 |
|---|---|---|---|---|
| 张大爷 | 3-1-501 | 138xxxx | 1860元 | 2026-06-30 |
| 李阿姨 | 5-2-302 | 139xxxx | 0元 | 2026-12-31 |
每一行代表一条记录,每一列代表一个字段,字段类型是固定的(字符串、数字、日期)。这就是结构化数据。
结构化数据占企业数据总量的多少?大约15%-20%。
第二种:半结构化数据
特点:没有严格的表结构,但有自描述的标签(tag)来标识字段。
最典型的例子是 JSON 文件、XML 文件、电子邮件。比如下面这段 JSON:
{
"业主": "张大爷",
"房号": "3-1-501",
"报修": [
{"时间": "2026-04-15", "事项": "厕所漏水"},
{"时间": "2026-04-22", "事项": "门锁卡死"}
]
}
它不像 Excel 那样规整,也不像一篇散文那样自由,处于"二者之间"。
半结构化数据占企业数据总量的多少?大约5%-10%。
第三种:非结构化数据
特点:没有预定义的格式,无法用传统数据库直接存储。
最典型的例子:监控录像、业主语音留言、合同扫描件、微信群聊天记录、抖音短视频、CT影像等。
非结构化数据占企业数据总量的多少?高达 70%-80%。
3.3 三种形态的对比与考点
把三者放在一张表里对比:
| 维度 | 结构化 | 半结构化 | 非结构化 |
|---|---|---|---|
| 典型例子 | 关系型数据库表 | JSON/XML/邮件 | 视频/音频/图像/文档 |
| 存储方式 | RDBMS(关系型数据库) | NoSQL/文档数据库 | 对象存储/文件系统 |
| 检索难度 | 低(SQL一查就有) | 中(需要解析标签) | 高(需要AI识别) |
| 占比 | 15%-20% | 5%-10% | 70%-80% |
| 常见处理工具 | MySQL/Oracle | MongoDB/Elasticsearch | 阿里OSS/AWS S3 |
这个表至少能撑起选择题2-3分。请用三明治学习法的"复盘"环节,把它默写一遍。
3.4 案例锚点:清华园物业的"数据形态盘点"
【虚构案例提示】 本讲及后续80讲中所有"智慧邻里2.0项目""清华园物业""北京知知致用信息技术有限公司"等案例素材,均为培训教学所用的虚拟项目与虚构人物(详见第01讲首次案例声明)。如出现项目名、社区名、公司名或人名雷同,纯属巧合,如有侵权,请联系老孙删除处理。
清华园物业现在到底有哪些数据?我让张主管做了一次盘点:
结构化数据:
- 1860户业主基本信息(姓名、身份证、电话、房号)
- 物业费缴费记录(金额、时间、缴费方式)
- 停车场进出记录(车牌、时间、收费)
半结构化数据:
- 与业主的微信沟通记录(带时间戳的文本)
- 报修工单(带JSON结构的事件流)
- 物业APP的用户行为日志
非结构化数据:
- 220路摄像头每天产生的视频流(约2TB/天)
- 业主投诉的语音录音
- 物业公司的纸质合同扫描件
- 业主大会的会议纪要文档
张主管做完这份盘点,第一次意识到:"我们公司管的不只是1860户业主,更是 每天TB级的数据资产!"
请你记住这个意识:对一个组织来说,盘点数据资产,是数据治理的第一步。
3.5 随堂自检(第1组)
请回答:
- 你公司财务系统里的"应付账款明细表"是什么形态的数据?
- 你手机里的微信聊天记录是什么形态的数据?
- 你公司的客服中心录音是什么形态的数据?
答案见本讲末尾。
四、第二层:数据如何变成信息——加工的"四步法"
4.1 加工,是数据的宿命
第01讲我说过一句话:数据→信息,加工方式是"赋予上下文"。
但"赋予上下文"听起来太抽象。我把它再细化一层,给你一个 可操作的"四步法":
- 筛选:从海量数据里挑出和当前问题相关的部分
- 清洗:去除错误、重复、缺失的数据
- 聚合:按维度(时间、空间、对象)汇总数据
- 解读:赋予数据业务含义,形成判断
这"四步法"是 整个数据治理(第18-20讲)和数据分析的底层逻辑,请你优先理解。
4.2 用"清华园物业月报"演示四步法
清华园物业每月要做一份运营月报,给业委会汇报上个月情况。我让张主管把"物业费收缴"这一项的数据加工过程拆开来给你看:
第一步:筛选
从总系统里筛选出"上月所有业主的缴费记录",原始数据有 5728 条(包含部分历史数据、误录入数据)。
第二步:清洗
去除:
- 重复缴费记录(系统bug导致的双扣):47条
- 测试数据(IT维护时留下的):12条
- 缺失关键字段(比如没有房号的):8条
清洗后剩 5661 条 有效记录。
第三步:聚合
按多个维度聚合:
- 按时间:上月共 1638 户 缴费(一户可能多次缴)
- 按楼栋:12栋楼分别统计缴费户数和金额
- 按缴费渠道:现金 12%,转账 28%,APP 60%
- 按缴费状态:及时缴费 85%,逾期缴费 11%,未缴 4%
第四步:解读
张主管在报告里写:
"上月物业费收缴率为 88%,较前月提升3个百分点;其中APP缴费占比首次突破60%,说明业主对线上化接受度提升;但仍有4%(约74户)未缴,主要集中在5号楼和8号楼,建议下月重点跟进。"
注意最后这段解读——它不再是冷冰冰的数字,而是包含了"判断+建议"的信息。这就是从数据到信息的关键跃迁。
4.3 一个细节:信息消除了"不确定性"
教材给信息下的定义里有一句话:"信息消除了数据中的不确定性"。
很多学员看到这句话都晕,我帮你翻译一下:
数据本身是中立的、模糊的、需要解读的。当你把数据整理出来、看出规律、做出判断之后,你心里那种"这事儿到底咋样"的疑问就消失了。疑问消失的过程,就是不确定性消除的过程,就是信息产生的过程。
举个例子:
- 数据:业主张大爷的物业费余额 = 0
- 信息:张大爷已经按时缴清本期物业费
数据本身不告诉你"张大爷有没有交"——余额可能是欠了零(已交清)也可能是欠了一万(已欠到底)。当你结合"余额=0且不欠费"这个上下文,你就消除了"张大爷交没交"这个不确定性,得到了一条信息。
这就是信息的本质:在某个具体决策场景下,消除了某种不确定性的数据。
4.4 信息的"七大属性"再深挖
第01讲我列过信息的特征。这一讲我把它们提炼为更贴近考试的"七大属性",并给每条都配一个真题情景:
属性1:客观性
信息一定有客观源头,不是凭空编造的。
考点警示:考题中常出现"该信息是基于市场调研得出的"、"该信息来自系统日志"等表述。如果题目说"信息是凭直觉判断的",那这个表述就不符合客观性。
属性2:时效性
信息会随时间衰减价值。
举例:上周的天气预报信息今天就没用了;昨天的股票实时行情,今天的价值大幅缩水;但 历史信息可以归档为知识资产——这是后面"数据仓库"的逻辑。
属性3:层次性
同一份原始数据,按不同维度聚合,会产生不同层次的信息。
举例:张大爷的缴费记录(个人层)→ 5号楼缴费率(楼栋层)→ 全社区缴费率(社区层)→ 海淀区物业行业缴费基准(区域层)。
属性4:可传递性
信息可以从一个主体传递给另一个主体,且传递不必然损失。
举例:你把"明天有暴雨"这条信息告诉同事,你自己并没有失去这条信息。这是信息和物质资产的本质差别。
属性5:可加工性
信息可以被进一步处理、组合、重构。
举例:把"业主缴费率"和"业主满意度"两条信息合并分析,可以得出"缴费率与满意度正相关"这条更高层次的信息。
属性6:共享性
信息可以被多个主体同时使用。
举例:智慧邻里APP的"今日通知",可以同时被1860户业主使用,不会因为有人看了别人就看不到。这是共享性的体现。
属性7:价值性
信息的价值取决于它能消除多少不确定性、能支撑多少决策。
举例:一条提前24小时的暴雨预警,对物业来说价值数万元(可以提前布置防汛物资);同样这条信息,提前1小时给的话,价值大幅缩水。
口诀:客时层传,加共价——"客时层传加共价"。考前你能在30秒内默写出来,就比别人多2-3分。
4.5 随堂自检(第2组)
请回答:
- 你周一早上看到天气预报"周三大雨",到了周四这条消息还是不是"信息"?为什么?
- 你公司的销售业绩报表是面向所有员工开放的,这体现了信息的哪个属性?
- 一份过时三年的市场调研报告,在今天还有价值吗?为什么?
答案见本讲末尾。
五、第三层:信息如何变成知识——四种知识分类
5.1 知识不是"信息的累积"
很多人以为,看的信息多了,自然就有知识了。
错。
信息的累积只是"知道得多",知识的形成需要"提炼出规律"。
我打个比方。一个人如果天天看新闻,知道国家又出台了什么政策、哪只股票涨了、哪个明星结婚了,他可能"知道得多",但他不一定有"知识"。
真正的知识,是这样的:
"近五年,国家每出台一次房地产宽松政策,二线城市的二手房成交量平均会在30天内提升15%-20%,并持续3-6个月。"
这才是知识——它有规律、有数字、有时间窗、有适用范围、可以指导决策。
信息回答"是什么",知识回答"为什么、怎么样、如何做"。
5.2 知识的两大分类法
教材和考试中关于知识,有两种分类方式 必须掌握:
分类法1:按表达形式分——显性知识 vs 隐性知识
| 类型 | 定义 | 例子 | 传递难度 |
|---|---|---|---|
| 显性知识 | 能用语言、文字、图表清晰表达的知识 | 教材、操作手册、公司流程文件 | 易 |
| 隐性知识 | 只能在实践中体会、难以系统表达的知识 | 老师傅的"手感"、谈判技巧、销售直觉 | 难 |
这两个概念是日本管理学家野中郁次郎提出的,构成了 知识管理(KM) 的理论基础。
为什么这个分类重要?
因为一个组织最大的知识资产,往往藏在 隐性知识 里。比如清华园物业的老员工赵师傅,他干了20年水暖工,能听一下水管的声音就知道是哪一段漏水。这种"听声辨漏"的能力,没法写在操作手册里。
当赵师傅退休或者离职,组织就会失去这部分知识。这就是为什么很多企业花大钱搞"知识管理系统"——本质上是在抢救隐性知识。
分类法2:按内容性质分——四象限模型
按"事实/概念/原理/方法"四个维度,可以把知识分为四种:
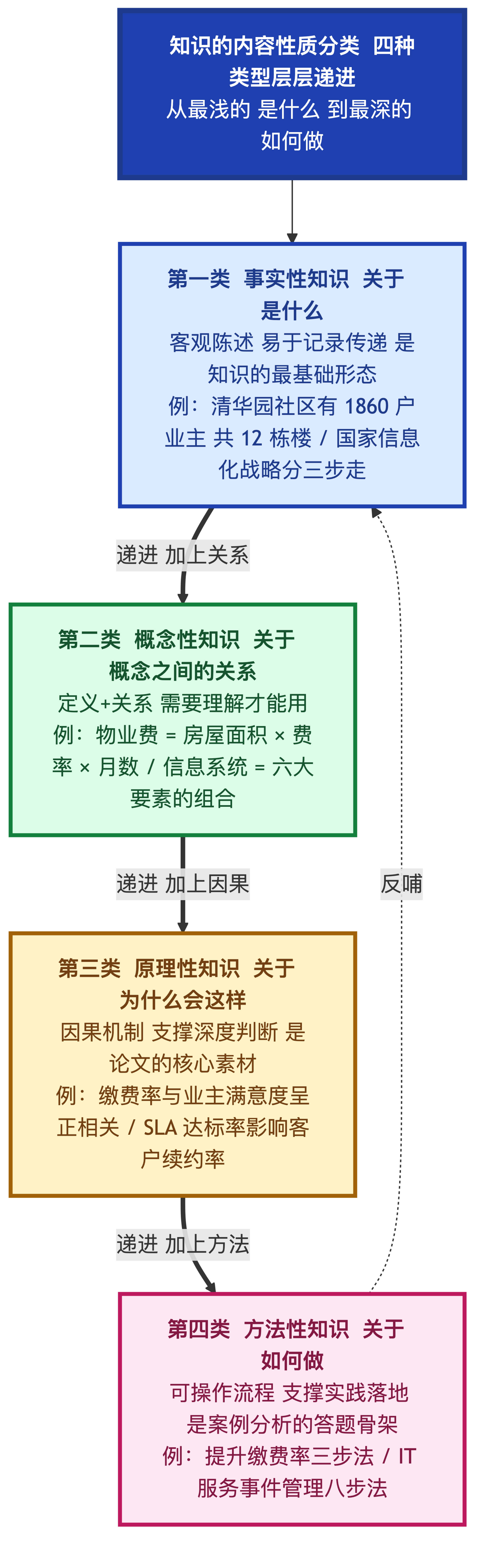
| 类型 | 定义 | 例子(清华园物业场景) |
|---|---|---|
| 事实性知识 | 关于"是什么"的知识 | 清华园社区有1860户业主 |
| 概念性知识 | 关于"概念之间关系"的知识 | 物业费=房屋面积×费率×月数 |
| 原理性知识 | 关于"为什么会这样"的知识 | 物业费收缴率与业主满意度正相关 |
| 方法性知识 | 关于"如何做"的知识 | 提升缴费率的"三步催收法" |
考点提醒:案例分析里如果让你"分析XX企业的核心知识资产",你必须能从这四个维度去拆解。
5.3 隐性知识的"显性化"——SECI模型
野中郁次郎还提出了一个非常重要的模型,叫 SECI模型,描述了隐性知识和显性知识之间的相互转化路径:
- Socialization(社会化):隐性→隐性。例如老师傅带徒弟的师徒制
- Externalization(外化):隐性→显性。例如让老师傅把经验写成手册
- Combination(组合):显性→显性。例如把多份手册整合成体系
- Internalization(内化):显性→隐性。例如新员工读手册并形成自己的工作直觉
这是论文常用素材。如果你将来写关于知识管理、人力资源、IT服务管理的论文,SECI模型可以作为理论框架直接套用。
5.4 案例锚点:清华园物业的"知识断层"
我让张主管对清华园物业的知识资产做了一次盘点,发现了一个惊人的事实:
显性知识:
- 物业管理操作手册(200页,2018年制定,至今未更新)
- 应急响应流程文件(30页)
- 业主入住指南(10页)
隐性知识:
- 赵师傅的水暖维修经验
- 客服小张应对投诉业主的话术
- 工程主管对小区管线分布的"地图记忆"
- 老物业经理对业主关系的"江湖经验"
问题来了:
显性知识里几乎没有最近五年的更新;隐性知识则全部依附在四五个老员工身上,一旦他们离职,组织就会瞬间"失忆"。
这是清华园物业最大的隐患。
知知致用在做智慧邻里2.0项目咨询时,方姐特别给王主任写了一份《知识资产保全建议书》,建议物业公司:
- 启动"老员工经验外化"项目,由方姐团队访谈记录
- 建立内部知识库系统,把隐性知识系统化沉淀
- 设立"师徒制",新员工跟老员工搭班半年
- 关键岗位设置AB角,避免"一人离职即知识断档"
王主任看完这份建议书,当天拍板批了20万预算。
这就是系统规划师的价值——他能看到老板看不到的"知识黑洞"。
5.5 随堂自检(第3组)
请回答:
- 一位老中医的"望闻问切"诊断技巧,属于显性还是隐性知识?
- 你公司的财务流程手册,属于事实性、概念性、原理性还是方法性知识?
- SECI模型中,"老师傅写经验手册"对应哪个环节?
答案见本讲末尾。
六、第四层:知识如何升华为智慧
6.1 智慧 = 跨场景的判断力
到了 DIKW 的最高层,"智慧"这个词听起来很玄。我用最朴素的话翻译给你:
智慧是一种"跨场景的判断力"。
知识,是在 特定场景 里"知道怎么做对"。
智慧,是在 任何场景 里"知道怎么做对"。
举个例子。
知识层:
"提升物业费收缴率的方法是:及时短信提醒+APP一键缴费+逾期罚息"——这是在物业行业里有效的具体方法。
智慧层:
"提升任何'被动支付场景'下的支付率,核心在于:降低支付摩擦、提高违约成本、建立长期关系"——这是可以应用到物业、信用卡还款、订阅服务等多个场景的普适原则。
智慧之所以是"智慧",就在于它能跨越具体场景,被复用到完全不同的领域。
6.2 智慧的三个特征
教材里关于智慧的描述比较少,但考试和论文里经常涉及。我把"智慧"的三个特征整理出来:
特征1:抽象性
智慧已经脱离了具体的事实细节,是高度抽象的原则、规律、价值观。
特征2:迁移性
智慧可以从一个领域迁移到另一个领域,不受行业限制。
特征3:决策性
智慧最终要落到决策上——它不是用来"知道"的,而是用来"做选择"的。
6.3 智慧形成的路径
一个组织或个人,如何从知识升华到智慧?
我总结为 "三抽三跨":
- 抽象一次:从单一案例的方法,抽象出该领域的方法论
- 抽象二次:从该领域的方法论,抽象出该问题域的原则
- 抽象三次:从该问题域的原则,抽象出普适的价值观
- 跨场景验证:在新场景中验证原则的适用性
- 跨行业迁移:把原则从原行业迁移到新行业
- 跨时间沉淀:经过3-5年时间检验仍然有效
这"三抽三跨",就是 企业级智慧资产的形成路径。
6.4 案例锚点:知知致用的"咨询智慧"
我作为知知致用的CEO,可以给你分享一些一手经验。
我们公司过去八年做过大约40个数字化转型咨询项目,覆盖物业、教育、医疗、制造、政府、零售六个行业。
最初我们是在每个行业积累 知识——教育行业怎么做、医疗行业怎么做……每个行业一套。
后来我们开始 跨行业总结,发现所有行业的数字化转型,本质上都遵循 三个共通原则:
- 业务先行原则:先讲清楚业务问题再谈技术
- 小步快跑原则:用2-3个月一个迭代周期,避免"大爆炸"
- 数据治理优先:数据治理走在系统建设之前
这三条原则,就是知知致用的 企业级智慧。
它已经不属于"教育行业知识"或"医疗行业知识"了,它属于"任何行业的数字化转型"。这种智慧,才是一家咨询公司的核心资产。
为什么我把这个故事讲给你听?
因为你将来作为系统规划师,你的真正成长方向,不是积累"某个行业的知识",而是积累"跨行业的智慧"。
这是这本证书背后真正的价值。
七、DIKW 整体演进路径与"四道断层"
7.1 整体演进路径
把 DIKW 四个层级串起来,就是这样一条 认知跃迁 的路径:
每一次跃迁,都需要一种 加工能力:
- 数据→信息:结构化加工能力(清洗、聚合、解读)
- 信息→知识:规律提炼能力(识别模式、形成判断)
- 知识→智慧:抽象迁移能力(跨场景、跨行业、跨时间)
7.2 大多数组织的"四道断层"
我观察过不少企业,发现绝大多数组织都卡在 DIKW 模型的中间某一层,无法继续向上跃迁。这就是"四道断层"现象。
断层一:数据→信息(约30%的组织卡在这里)
表现:有大量数据但提取不出有用信息。比如清华园物业之前装了220路摄像头,每天产生TB级视频数据,但因为没有AI分析能力,99%的视频从来没有被人看过。
根因:缺乏数据加工能力——没有BI工具、没有数据分析师、没有规范的报表体系。
断层二:信息→知识(约40%的组织卡在这里)
表现:能出报表但出不了规律。每月看着一堆KPI,但说不出"为什么这个月好、为什么那个月差"。
根因:缺乏分析与归纳能力——没有人去问"为什么",没有人在多份报告之间寻找关联。
断层三:知识→智慧(约25%的组织卡在这里)
表现:在自己行业内是专家,但跨行业一筹莫展。一旦行业出现颠覆性变化,组织就慌了。
根因:缺乏跨场景抽象能力——所有人都被"行业经验"绑架,没有人跳出来看本质。
断层四:智慧→实践(约5%的组织卡在这里)
表现:高层有智慧,但落地动作变形。CEO读了无数本管理书,结果到了执行层全都"水土不服"。
根因:缺乏组织能力——智慧没有被有效转化为流程、制度、考核。
7.3 案例锚点:清华园物业的 DIKW 跃迁路线图
方姐给清华园物业做了一份《DIKW跃迁三年路线图》:
| 阶段 | 时间 | 跃迁目标 | 关键动作 |
|---|---|---|---|
| 第一阶段 | 2026下半年 | 跨越"数据→信息"断层 | 建设BI看板、统一数据口径、设立数据分析岗 |
| 第二阶段 | 2027 | 跨越"信息→知识"断层 | 建设知识库系统、定期分析报告、形成"运营手册2.0" |
| 第三阶段 | 2028 | 跨越"知识→智慧"断层 | 跨小区数据对比、参与行业研究、形成"清华园模式" |
这份路线图,就是一个真实的"系统规划师"思考方式。
它没有上来就讲技术、讲产品、讲投资额,而是先讲 认知层级的跃迁——这才是数字化转型的本质。
八、考点聚焦
8.1 选择题考点
| 考点 | 命题方向 | 真题锚定 |
|---|---|---|
| 数据三大形态 | "下列属于非结构化数据的是" | 2018/2021/2022高频 |
| 数据 vs 信息 | "下列属于信息而非数据的是" | 多年高频 |
| 信息的属性 | "信息的下列特征中不包括" | 2017/2019 |
| DIKW 模型层级 | "DIKW模型中,从X到Y的转化方式是" | 2021/2022 |
| 显性 vs 隐性知识 | "下列属于隐性知识的是" | 2019/2022 |
| 知识管理 SECI模型 | "SECI模型中XX环节的含义是" | 2022 |
8.2 案例分析关联
本讲为以下案例分析主题打基础:
- 数据治理类:必考"数据形态盘点"+"数据质量分析"
- 数字化转型类:必考"DIKW跃迁路径分析"
- 知识管理类:考查"显隐性知识识别"+"知识资产盘点"
典型出题模式:
"请结合DIKW模型,分析某企业当前数字化建设处于什么阶段,并提出向上跃迁的建议(10分)"
这种题型,你必须能在 5分钟内 写出完整的分析框架。
8.3 论文关联
本讲内容支撑以下论文主题:
- 论数据治理体系建设与数据要素价值化(必用 DIKW 框架)
- 论企业知识管理体系建设(必用 SECI模型 + 显隐性知识分类)
- 论企业数字化转型规划(必用 DIKW 跃迁断层分析)
九、论文素材播种
9.1 可移植素材片段(300字版)
项目背景模板(关于数据治理类论文):
我作为系统规划师,参与了某企业数据治理体系建设项目。项目立项前,我通过DIKW模型对企业当前数据资产做了系统盘点:在数据层,企业沉淀了TB级业务数据,但其中非结构化数据占比超过70%,长期处于"沉睡"状态;在信息层,仅有少数财务和销售口径形成规范报表;在知识层,业务规律和经验主要依附在少数老员工身上,存在严重的"知识断层"风险;在智慧层,缺乏跨业务、跨行业的判断框架。基于这一诊断,本项目将"打通数据→信息→知识→智慧四层跃迁"作为总目标,按"数据资产盘点—信息加工能力建设—知识沉淀机制建立—智慧文化养成"的四步推进。
项目结果模板:
项目实施一年后,企业数据资产盘点率从30%提升至92%;BI报表覆盖率从15%提升至80%;建立了包含47类业务规律的内部知识库;启动了三个跨业务的"智慧专题研究"。整体数字化成熟度从B级跃升至A级。
请你把这两段保存到自己的论文素材库里。
9.2 重点理论框架收纳
请你把下列三个理论框架抄写到笔记本上:
- DIKW模型:数据→信息→知识→智慧的认知跃迁
- 数据三形态:结构化、半结构化、非结构化(占比 20/10/70)
- SECI模型:社会化→外化→组合→内化的知识转化
这三个框架,80讲下来你至少会用到 30 次。
十、课后任务
10.1 必做思考题
思考题1:
请用 DIKW 模型 分析你所在的组织(公司、单位、社区都可以),写一段300-500字的诊断:
- 你的组织当前主要卡在哪一道断层?
- 跨越这道断层需要什么关键动作?
- 你作为"未来的系统规划师",能贡献哪些建议?
思考题2:
请盘点一下你所在岗位上的 隐性知识——那些只有你(或少数老员工)才会、写不进操作手册的"独门技巧"。
- 列出 3-5 条
- 思考:如果你明天离职,组织会损失什么?
10.2 刷题任务
完成历年真题选择题 第1章 第16-30题(重点关注数据形态、信息特征、DIKW模型相关题目)。
10.3 实践任务(可选)
如果你的工作环境允许,请你按 数据加工四步法(筛选—清洗—聚合—解读)做一次小型分析:
- 选一个你工作中熟悉的数据源(销售记录、客户反馈、报修工单等)
- 走完四步法,输出一份300字以内的"信息小报告"
把这份报告保存好,第18-20讲讲数据治理的时候我们会回头看你的实操。
十一、随堂自检参考答案
第1组:
- "应付账款明细表" 是 结构化数据。它有固定字段(供应商、金额、账期、状态),存储在ERP数据库的关系表中。
- "微信聊天记录" 是 半结构化数据。它有时间戳、发送者、接收者、消息类型等元数据,但消息内容本身可以是文字、图片、语音等多种类型。
- "客服中心录音" 是 非结构化数据。它是音频流,无法用传统关系数据库直接存储和检索,必须经过语音识别(ASR)才能转为可检索的文本。
第2组:
- 不是有效信息了。这条信息因为"时效性"已经过期。它从信息退化为历史数据。但如果归档分析,它可以作为"建立暴雨预警准确率统计"的基础数据。
- 体现了信息的 共享性。同一份业绩报表可以被多人同时使用,且使用过程不会损耗它。
- 价值大幅降低,但仍可能有部分价值。它的"时效性"已过,但其中关于市场结构、竞争格局的部分判断,可能作为历史参照仍有价值。这是信息"价值性"和"时效性"共同作用的结果。
第3组:
- 隐性知识。"望闻问切"高度依赖经验和直觉,难以用文字完全描述,必须靠师承+实践来传递。
- 方法性知识。流程手册告诉你"如何做"——按什么步骤、用什么工具、达到什么标准。
- 对应 Externalization(外化) 环节——把老师傅头脑里的隐性经验,转化为可以传播的显性手册。
十二、下讲预告
下一讲我们要进入 第03讲:信息系统全家福——从"收银台"到"城市大脑"。
我会带你深度解读:
- 信息系统的 五大组成要素 在不同行业里的具体表现
- 信息系统的 诺兰六阶段成熟度模型——评估一个组织信息化处于哪个层级
- 信息系统的 生命周期管理——从立项到消亡的全过程
- 案例锚点:清华园物业到底处于诺兰模型的哪一阶段?
这一讲是 后续所有规划章节的"评估工具箱"。学不透它,到了第09讲讲ISP的时候你会找不到坐标。
请你今天先把本讲的内容沉淀好,再进入下一讲。节奏比速度更重要。
写在最后
第02讲就到这里。
如果你坚持读到这里,恭喜你又往前迈了一大步。我必须诚实地告诉你:第02讲的密度比第01讲大了不少——DIKW、数据三形态、信息七大属性、知识两大分类、SECI模型、四道断层……这些概念叠在一起,需要你花点时间去消化。
不要怕。
这就像吃一顿正餐,先有开胃菜(第01讲),再有主菜(第02讲)。主菜难嚼,但消化了之后,后面的章节会越来越顺。
节奏管理 比 学习速度 重要十倍。我宁愿你用三天慢慢嚼透第02讲,也不愿意你一晚上囫囵吞下五讲然后什么都没记住。
下一讲见。
本讲完
—— 老孙